作为数据产品经理,你需要搞懂这4大模块
文章从数据全生命周期的四大模块展开,对数据的采集、处理、存储和分析作了简要的分析介绍。希望对你有所帮助。

前面我们学习了4个步骤,用O *** 和之一关键指标法来确定核心指标,接下来我们聊聊数据全生命周期。
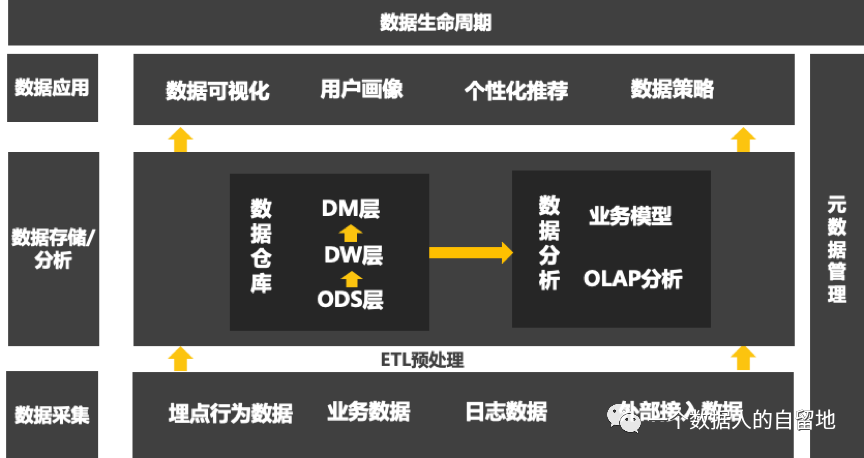
接下来分别介绍这几大模块:
数据采集
数据预处理——ETL
数据存储——数仓
数据分析——OLAP/业务模型
一、数据采集按数据来源分,可将数据分为如下几个类型:
埋点行为数据:通过埋点的方式,采集到的一些行为数据,如浏览、点击、停留时长等
业务数据:伴随着业务产生的数据,核心是生产系统内存储的业务表单数据
日志数据:一般是web端日志记录的数据
外部接入数据:从第三方获得的数据
按数据类型可分为:结构化数据、半结构化数据、非结构化数据。
(1)结构化数据
一般是从内部数据库和外部开放数据库接口中获得,一般都是存储产品业务运营数据以及用户操作的结果数据,比如注册用户数、下单量、完单量等数据。这类数据格式规范,典型代表就是关系数据库中的数据,可以用二维表来存储,有固定字段数,每个字段有固定的数据类型(数字、字符、日期等),每个字节长度相对固定。这类数据易于维护管理,同时对于查询、展示和分析而言也是最为方便的一类数据格式。
(2)半结构化数据
应用的点击日志以及一些用户行为数据,通常指日志数据、xml、json等格式输出的数据,格式较为规范,一般是纯文本数据,需要对数据格式进行解析,才能用于查询或分析数据。每条记录预定义规范,但是每条记录包含信息不同,字段数不同,字段名和字段类型不同,或者还包含着嵌套的格式。
(3)非结构化数据
指非纯文本类数据,没有标准格式,无法直接解析相应值,常见的非结构化数据有富文本、图片、声音、视频等数据。这类数据除非是要进行高级的文本挖掘或者多媒体数据挖掘,否则对于日常的数据统计与分析而言,非结构化数据没有分析价值。一般不会将非结构化数据以二进制形式存入数据仓库,数据仓库之父Inmon的建议是数据仓库中只需要存储非结构化数据的元数据。一般将非结构化数据存放在文件系统中,数仓中记录数据的信息,如标题、摘要、创建时间等,方便进行索引查询。
二、数据预处理——ETL ETL即Extract Transform Load,描述数据抽取、转换、加载的过程。
数据抽取:把数据从数据源中读出来
数据转换:把原始数据转换成期待的格式和维度
数据加载:把处理后的数据加载到目标处,如数据仓库中
数据仓库从各数据源获取数据以及在数据仓库内的数据流转和流动都可以认为是ETL过程,ETL是数据仓库的流水线,也可以认为是数据仓库的血液,它维系着数据仓库中数据的新陈代谢,而数据仓库日常的管理和维护工作大部分精力是保持ETL的正常和稳定。
KettleKettle是常用的ETL处理开源免费工具,其中文名叫水壶,该项目的主程序员MATT希望把各种数据放到一个壶中,然后以指定的格式流出。Kettle是纯Java编写,可以在Windows、Linux、unix上运营,数据抽取效率高效稳定,开放源代码,便于二次开发包装。但其数据抽取速度和大数据处理方面的能力比起powercenter、informatica、datastage等商业软件要慢。
三、数据存储——数据仓库数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持。数据仓库本身不生产任何数据,同时也不消费任何数据,数据来源于外部,并且开放给外部应用。这就是为什么叫数据仓库,而非数据工厂的原因。
数据仓库基本架构数据仓库基本架构包含数据流入/流出的过程,可以分为三层:源数据、数据仓库、数据应用。
(1)ODS(Operational Data Store)数据操作层
用于原始数据在数据平台的落地,这些数据从数据结构、数据之间的逻辑关系上都与雨啊是数据层基本一致。在源数据进入这一层时,通常要进行数据清洗,如业务字段提取、去掉不用字段、脏数据处理等。默认保留近30天的数据,表命名规范为:ods_主题_原表名。
(2)DIM(Dimension Data Layer),数据维度层
相关文章

入职数据产品经理第一天,同事问了我3个问题
什么是数据产品经理?数据产品经理有什么能力要求?数据产品经理的未来发展什么?文章围绕这三个问题进行陈述分析,希望看完能对你有所帮助。 最近,前同事老曹跳槽到去了一家初具规模的互联网公司,作为刚入职公...
Copyright Your WebSite.Some Rights Reserved.
 免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!
免责声明:本站所发布的任何网站,全部来源于互联网,版权争议与本站无关。仅供技术交流,如有侵权或不合适,请联系本人进行删除。不允许做任何非法用途!